🚀【工程】服务性能优化入门与实践指南
一、前言
在后端场景中,服务是一种提供特定功能的模块或系统,通过 REST API、RPC 等方式对外提供接口。服务可以独立运行,也可以和其他服务共同协作,构成一个庞大的系统。常见的服务有鉴权服务、搜索服务、数据库服务、广告召回服务等。
服务是整个系统的重要组成部分,为前端应用和其他上游服务提供支持,必须保证稳定可靠。现代服务通常需要应对高并发的请求、处理大规模的数据。随着业务和架构复杂度的增加,性能问题也会随之出现。这不仅会影响用户体验,也可能影响整个系统的稳定性。因此,服务性能优化显得尤为重要。通过优化服务性能,一方面可以降低延迟,保障服务的高可用性,提升用户体验,另一方面可以减少 CPU、内存等硬件资源的消耗,节约成本。
在这篇文章中,我们将围绕「服务性能优化」展开讨论,从代码、系统、架构等层面,探索服务性能优化的最佳实践。
二、相关术语
衡量服务性能的指标
- 延时 Latency:分成客户端和服务端两个视角,客户端即调用方,服务端即被调用方。客户端延时,表示调用方从发出请求到收到服务响应所需的时间。服务端延时,表示服务从收到请求到发出响应所需的时间。前者比后者多出两次网络传输、以及序列化 / 反序列化的时间。客户端延时通常有一个上界,这是因为客户端会设置超时时间。而服务端延时没有这样的上界,因为服务端无法感知客户端是否已经超时结束。显然,延时越低越好。
- 吞吐量 Throughput:服务在一段时间内处理请求的能力,单位通常是 QPS (Queries Per Second) 或 TPS (Transactions Per Second)。QPS 指每秒钟能够处理多少个查询请求,常用于数据库、搜索引擎等场景。TPS 指每秒钟能够完成多少个事务或操作,通常用于交易系统、支付系统等场景。在保证稳定性的前提下,吞吐量越高越好。
- 错误率 Error Rate:服务出现错误的请求数占总请求数的百分比。错误率直观展示了服务的稳定性,越低越好。
- 资源使用率:运行服务的主机或容器上各种系统资源的使用率,包括 CPU、内存、磁盘和网络等。不同服务对于资源的需求不同,例如 CPU 密集型服务更注重 CPU 的使用率,内存密集型服务则更注重内存的使用率。资源使用率越高,说明服务的负载越大,可能导致服务响应变慢、稳定性降低。因此,各项资源使用率越低越好。某些场景下可以用 A 资源兑换 B 资源,比如某个定制版的 Golang 编译器通过优化内存管理模型,用冗余的内存来兑换 CPU,效果是 (CPU 50%, MEM 10%) → (CPU 30%, MEM 60%)。对于 CPU 密集型服务来说,这个内存到 CPU 的兑换比是很划算的。
SLO、SLA
SLO 和 SLA 也是服务性能优化中两个常见的概念:
- SLO (Service Level Objective):服务水平目标,通常是一个数值或范围,比如稳定性达到 99.9%,即 3 个 9,表示一年内的停机时间最多为 8 小时 45 分钟、一个月内的停机时间最多为 43.2 分钟。注意,「SLO 达到 3 个 9」和「错误率低于 0.1%」并不是等价的。
- SLA (Service Level Agreement):服务水平协议,是由服务提供方和服务使用方达成的一份协议,约定了服务提供方应该达到的最小服务水平,若达不到应有补偿。
- SLO 是为了满足 SLA 而制定的。SLO 可以看作是 SLA 的内部指标,用于衡量服务是否符合 SLA 中约定的服务水平要求。
avg、pct50、pct99
当我们观测服务性能指标时,通常会查看一个统计值,比如所有请求的平均延时、集群中所有主机的平均 CPU 使用率等。
avg(平均值) 是所有数据的算术平均值,可以帮助我们快速了解服务性能的整体水平,但是不够准确,容易被异常值影响。pct50(中位数) 是位于所有数据最中间的一个值。和avg相比,pct50更稳定,不易受异常值影响。适用于数据分布不均匀、有异常值或者极值的场景。pct99(百分位数) 是位于所有数据第 99% 位置的值,比如 100 个请求中的前 99 个请求,它们的延时都比pct99小,只有最后 1 个请求的延时比pct99大。pct99可以帮助我们快速发现一些问题,比如存在大包体、慢查询等长尾请求,或者集群中有异常实例。- 类似的,还有
pct90、pct999等指标。
总之,pct{n} 反映了数据的分布情况,有助于我们了解服务在极端情况下的性能表现。实际场景下,我们需要同时关注 avg、pct50、pct99 等指标,以获取更全面的性能数据。
基准测试、压力测试
基准测试 (Benchmarking) 是一种衡量系统性能的标准化方法。基准测试常用来验证性能优化效果:首先在系统上运行一系列测试程序,保存性能指标结果;然后在代码或硬件环境变化之后,再执行一次基准测试,以确定那些变化对性能的影响。
压力测试 (Stress Testing) 通过增加系统负载,测试系统在极端情况下的表现。压力测试可以帮助发现系统的性能瓶颈。常用的压测工具有 Apache JMeter、LoadRunner 等。
三、分析服务性能问题的工具
日志和监控
-
收集数据:通过日志和监控记录服务运行过程中的信息。这些信息既要包含时间戳、接口名、IP 地址、请求延时等通用信息,也要包含服务内部的具体数据,如每个子步骤的执行耗时、请求传入的数据量级等。
监控数据一般用 Metrics 框架来收集。一个知名的 Metrics 框架是 OpenTSDB。
Metrics 框架提供了存储时序数据和对时序数据进行聚合查询的功能:
- 时序数据:对于某一项数据,记录其在不同时间点的值。绘制出来是横轴为时刻、纵轴为值的折线图。
- 聚合查询:支持多种聚合方式 (avg、sum、p99 等) 和多种查询条件。
Metrics 框架提供了通用的 API,可以在应用程序中收集各种类型的指标,比如 counter、timer 等。Metrics 数据可以展示在 Grafana 看板中。
-
展示数据:对收集到的日志和监控数据进行处理,可视化地展示其中的各项关键指标。常用的可视化工具是 Grafana。
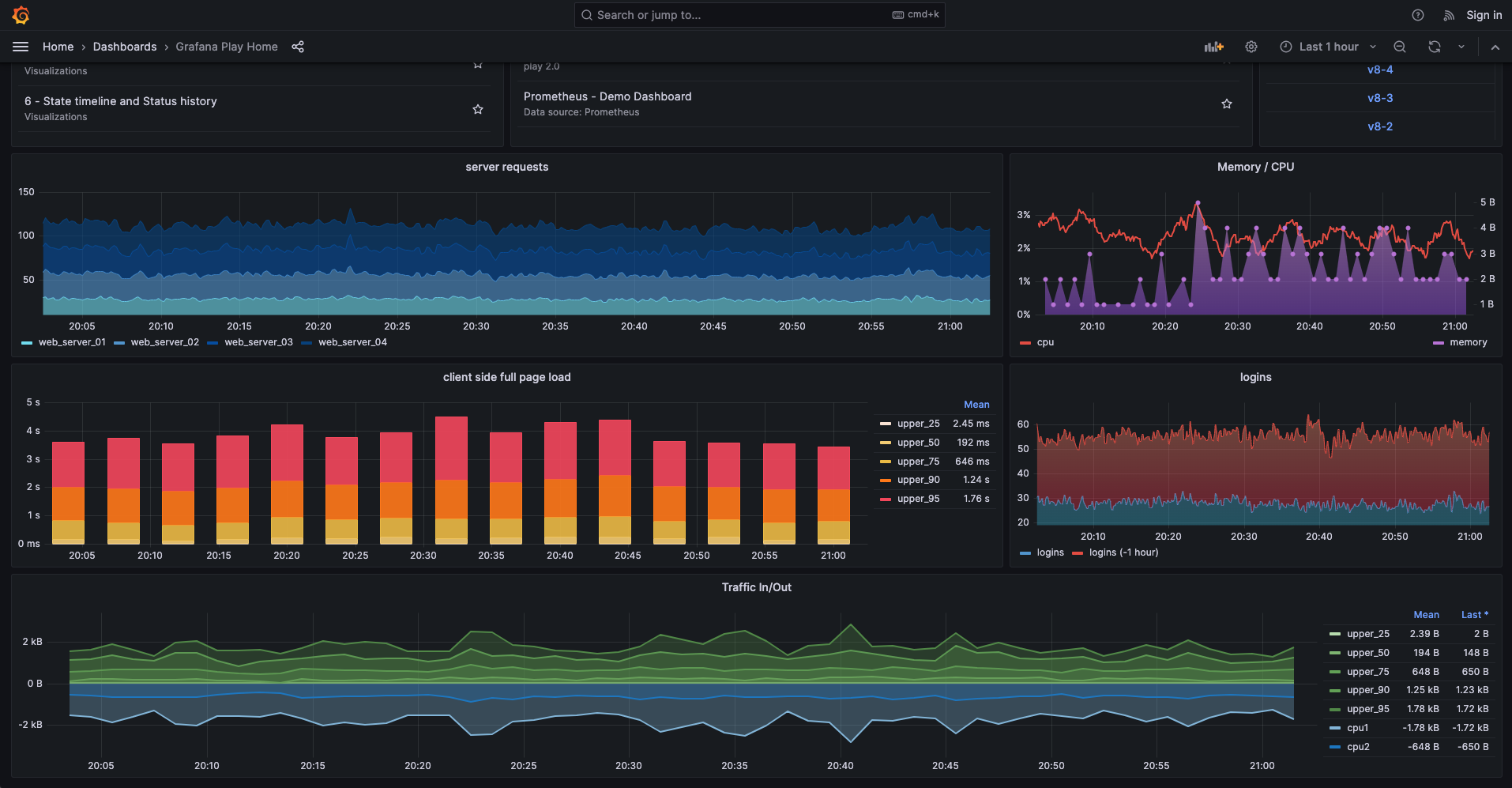
图片来源:Grafana Playground
-
分析数据:观察指标的
avg、pct99等分位数,分析是否有长尾请求或单点异常;观察指标随时间的变化情况,定位出现性能异常的时间;同时观察多项指标,发现指标之间的关联关系,比如某时刻请求量上涨,导致 CPU 利用率上涨,进而导致服务稳定性下降。
下面是几个分析数据的实际案例。
(1) 根据日志发现单点异常:
假设我们从服务集群上下载了一批请求日志:
192.168.0.1 - - [23/Sep/2021:14:45:32 +0800] "GET /api/v1/users?page=1&limit=20 HTTP/1.1" 200 3567 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" 0.504
192.168.0.2 - - [23/Sep/2021:14:45:33 +0800] "POST /api/v1/login HTTP/1.1" 200 256 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" 1.267
192.168.0.3 - - [23/Sep/2021:14:45:34 +0800] "DELETE /api/v1/user/123 HTTP/1.1" 204 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" 0.873
192.168.0.4 - - [23/Sep/2021:14:45:35 +0800] "PUT /api/v1/user/123 HTTP/1.1" 200 1343 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" 0.901
192.168.0.5 - - [23/Sep/2021:14:45:36 +0800] "GET /api/v1/products?id=1234 HTTP/1.1" 200 4382 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" 0.702
...
每行日志对应了一个请求,日志的第一列是处理该请求的服务主机 IP 地址,最后一列是处理该请求的耗时,单位是秒。我们可以这样统计每台主机处理请求耗时的 avg 指标:
awk '{ips[$1]++; total[$1]+=$NF} \
END {for (ip in ips) { \
avg=total[ip]/ips[ip]; \
n=ips[ip]; \
printf("%-15s requests: %-5d avg_time: %.3fs\n", ip, ips[ip], avg); \
} \
}' log.txt | sort -k3nr
以上命令执行后,会输出每个 IP 地址的请求数量和平均耗时,并按平均耗时从大到小排列。输出格式如下:
192.168.0.2 requests: 1011 avg_time: 2.267s
192.168.0.4 requests: 1103 avg_time: 0.901s
192.168.0.3 requests: 1021 avg_time: 0.873s
192.168.0.5 requests: 1007 avg_time: 0.702s
192.168.0.1 requests: 1097 avg_time: 0.504s
不难发现, 192.168.0.2 的平均耗时远大于其他主机。最简单的处理办法是重启或迁移它。
但上面从日志统计耗时的流程很繁琐。实际场景中,一般使用 Metrics 框架收集单个请求的耗时、每台主机的 CPU 利用率等指标,然后在 Grafana 中展示。
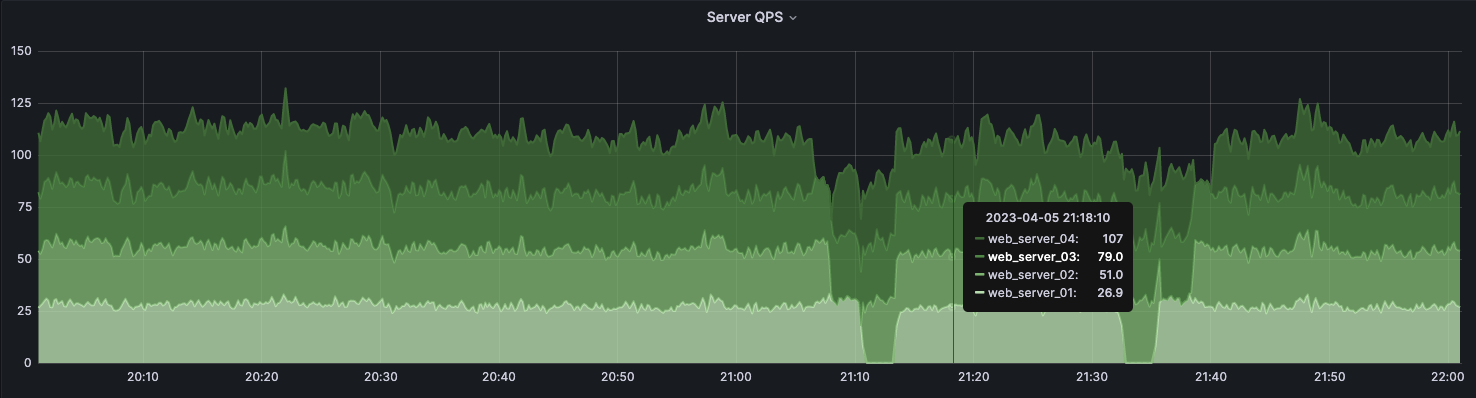
(2) 根据监控发现单点异常:
通过 Metrics 和 Grafana 可以更实时、更直观地发现单点异常。比如下图是一个服务单机 QPS 的 Grafana 看板,当有一条曲线远远高于 / 低于其他曲线时,说明对应的主机有单点异常。在这个场景下,很有可能是集群负载均衡器的问题。
火焰图
火焰图是一种性能分析工具,它以可视化的方式展示系统中的函数调用层级和执行时长。
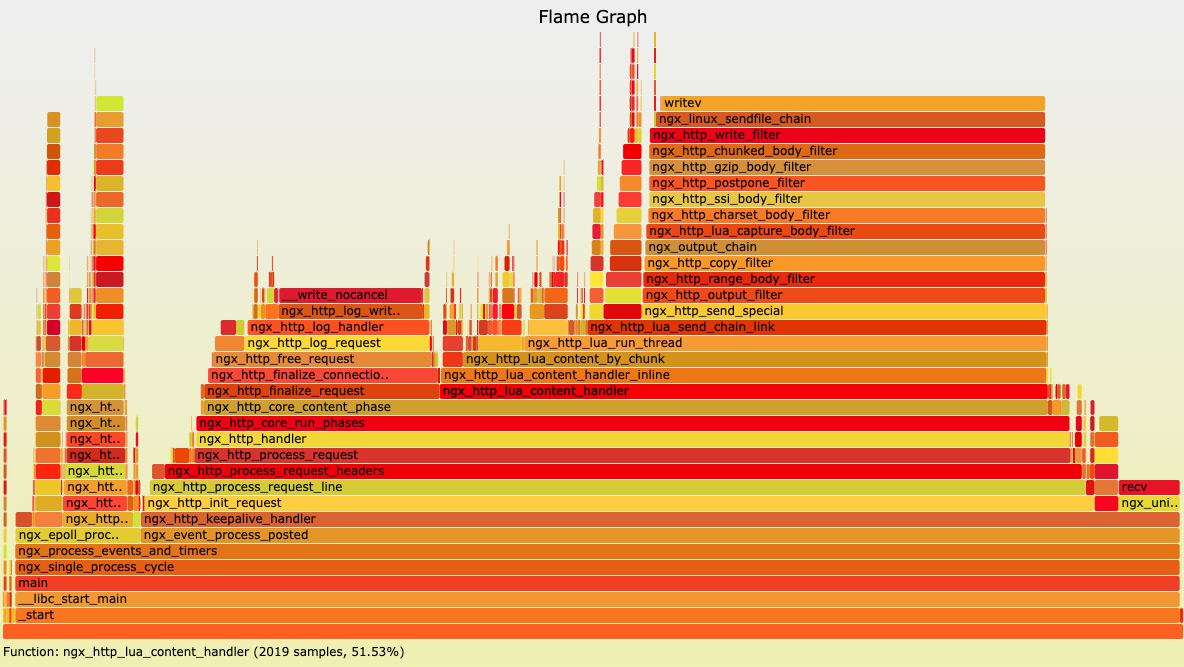
图源:http://openresty.org/download/user-flamegraph.svg
{kind=link}
火焰图是一张形如火炬的 SVG 图片。火焰图上的每个矩形代表了一个函数的执行过程,其宽度表示执行时间的长短。矩形从下向上表示函数的调用层次,底部是外层函数,顶部是被调用的函数。矩形颜色没有含义,只是为了便于区分。
显然,矩形的宽度越宽,该函数的执行时间就越长,表明该函数可能存在性能问题。我们需要寻找火焰图中最宽的矩形,针对性地优化代码。
生成火焰图时,首先需要使用 perf 或 DTrace 等命令,收集一份包含函数执行堆栈的数据报告。然后可以使用 Brendan Gregg 开发的 FlameGraph 或者 Google 开发的 pprof 等工具,根据收集到的数据生成火焰图。最后可以使用 d3-flame-graph 等工具,将静态的 SVG 文件转换成动态的 HTML 文件,以便深入分析。
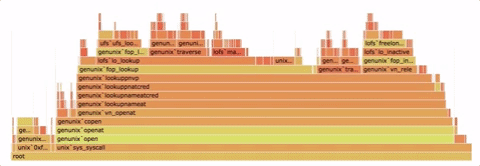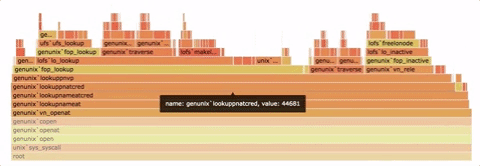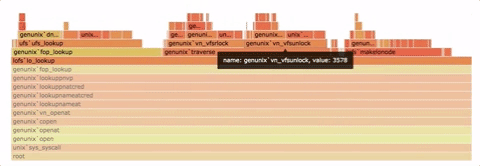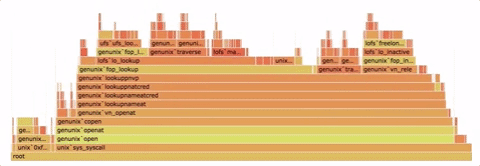
图源:https://github.com/spiermar/d3-flame-graph
火焰图不仅可以用来分析 CPU 热点,也可以用来排查内存泄漏问题。这里需要使用某些内存分配追踪工具,记录内存的分配和释放情况,然后基于这些数据生成内存火焰图。内存火焰图的矩形块颜色是绿色的,每个矩形块的宽度表示该函数内部分配的字节数。

图源:Memory Leak (and Growth) Flame Graphs - Brendan Gregg
最后介绍一下差分火焰图。差分火焰图可以对比不同时间段的两张火焰图的差异,以观察哪些函数的资源开销发生了变化。差分火焰图的形状和第二张火焰图相同,矩形块的颜色表示该函数资源开销 (占比) 的差异,红色代表增长,蓝色代表减少。

图源:Differential Flame Graphs - Brendan Gregg
差分火焰图可以用来定量分析某项性能优化工作是否有效,比如优化了一个热点函数后,应该能从差分火焰图上看到该函数的 CPU 开销有显著减少。此外,差分火焰图也可以用来排查内存泄漏问题,比如在一台发生内存泄漏的机器上,每隔一段时间采集一份内存数据报告,然后生成内存差分火焰图,便可以很直观地看出增长的内存来自哪里。
Perf
Perf 是 Linux 操作系统中一个强大的性能分析工具,可以用来追踪 CPU、内存和 I/O 等方面的性能问题。它的原理是利用 Linux 内核提供的系统调用接口,跟踪和记录各种事件的性能数据,并输出到文本文件中。Perf 命令可以和火焰图工具结合使用 —— 前者收集数据,后者可视化展示。
使用 perf record 命令,将程序的 CPU 执行情况记录到 perf.data 文件中:
perf record -p {pid} sleep 30
上面的命令表示采集指定 pid 的进程,持续 30s。可能的输出:
$ ./perf record -p 59 sleep 30
Lowering default frequency rate from 4000 to 1000.
Please consider tweaking /proc/sys/kernel/perf_event_max_sample_rate.
[ perf record: Woken up 55 times to write data ]
[ perf record: Captured and wrote 21.482 MB perf.data (462814 samples) ]
使用 perf report 命令,可视化地查看和分析数据。默认加载当前目录的 perf.data 文件:
perf report
一个可能的数据样例如下,从中我们可以看到每个函数执行占用的 CPU 百分比:
# Samples: 100K of event 'cycles:u'
# Event count (approx.): 1000000
#
# Overhead Command Shared Object Symbol
# ........ ....... ................. ..............................
#
38.02% my_prog libfoo.so.1.2.3 /usr/lib64/libfoo.so.1.2.3
9.21% Foo::bar()
8.08% Foo::baz()
7.12% Foo::qux()
6.61% Foo::quux()
4.48% Annex::foo()
2.22% Annex::bar()
0.30% Annex::baz()
0.01% std::string::operator[](unsigned long)
0.01% std::operator+(std::basic_string<char, std::char_traits<char>, std::allocator<char> > const&, char const*)
0.01% Annex::qux()
24.41% my_prog libbar.so.4.5.6 /usr/lib64/libbar.so.4.5.6
13.05% Bar::foo()
6.89% Bar::bar()
4.70% Bar::baz()
加载数据后,按 / 可以搜索函数名,会从高到低展示不同线程中该函数的 CPU 占比。
一般来说,我们可以很快通过 perf report 或火焰图定位到哪个函数是热点。接下来需要在机器指令级别深入分析产生性能热点的原因。在某个函数名上回车,可以进入该函数,查看每条机器指令的执行开销。以下是一个可能的数据报告:
------------------------------------------------
Percent | Source code & Disassembly of noploop
------------------------------------------------
: int main(int argc, char **argv)
: {
0.00 : 8048484: 55 push %ebp
0.00 : 8048485: 89 e5 mov %esp,%ebp
[...]
0.00 : 8048530: eb 0b jmp 804853d <main+0xb9>
: count++;
14.22 : 8048532: 8b 44 24 2c mov 0x2c(%esp),%eax
0.00 : 8048536: 83 c0 01 add $0x1,%eax
14.78 : 8048539: 89 44 24 2c mov %eax,0x2c(%esp)
: memcpy(&tv_end, &tv_now, sizeof(tv_now));
: tv_end.tv_sec += strtol(argv[1], NULL, 10);
: while (tv_now.tv_sec < tv_end.tv_sec ||
: tv_now.tv_usec < tv_end.tv_usec) {
: count = 0;
: while (count < 100000000UL)
14.78 : 804853d: 8b 44 24 2c mov 0x2c(%esp),%eax
56.23 : 8048541: 3d ff e0 f5 05 cmp $0x5f5e0ff,%eax
0.00 : 8048546: 76 ea jbe 8048532 <main+0xae>
[...]
从中可以看到,cmp 指令占用了大量的 CPU 时钟周期,原因是它位于一个循环体中。
下面是另一份数据报告,对应了一段「在哈希表中查找关键字」的代码:
0.00 : xor %edx,%edx
1.80 : mov $rdx,$r8
: _ZNKSt10_HashtableI1St4pair__equal_toI1ESt4hash_20_Default_
0.03 : mov (%rcx),%rax
0.03 : mov (%rax,%r8,8),%rax
18.60 : test %rax,%rax
...
14.78 : cmp 0x8(%rbx),%r14
...
💡 上面的 _ZNKSt10_xxx 是一个 C++ 符号名。使用 c++filt 命令可以将其转换为人类可读的形式。
从中可以看出,访存指令的开销很大,这表明哈希表在查找过程中经常失败。对应的优化手段有调整哈希函数、改进哈希冲突解决策略等,以减少哈希表的 miss 率。
按照类似的思路,我们可以利用 Perf 命令,在指令级别分析某个函数成为性能热点的原因。比如:某指令在循环中被频繁执行、某指令涉及访存操作、某指令依赖某些暂不可用的数据 (如锁)、某指令本身是一个多周期指令等。针对不同的问题,需要采用不同的优化方案。
最后,Brandan Gregg 有一篇非常详细的 Perf 命令使用指南,涵盖了 CPU 统计、事件分析、内核跟踪等话题,配合火焰图,基本可以排查出任意性能问题。建议深入阅读原文,此处不再展开。
pprof
pprof 是 Golang 官方提供的性能分析工具,可以生成 CPU、内存等多种类型的 Profiling 数据,支持以可视化的方式展示。pprof 内置了火焰图、函数调用图、表格等多种展示方式。
对于 Golang 服务的性能优化,建议使用 pprof,或者 pkg/profile 等开源库。
四、与性能优化相关的基础知识
后面几节将从不同层面讨论服务性能的优化手段。在此之前,有必要先了解一些基础知识。这些知识可以帮助我们更深入地理解程序性能优化的原理和方法,从而更有效地进行性能优化。
并行与并发
并行 (Parallelism) 和并发 (Concurrency) 都是计算机处理多个任务的方式:
- 并行是指在同一时刻,同时执行多个任务,这通常依赖多个处理器或核心。
- 并发是指在一段时间内,通过任务的交替执行来同时处理多个任务。并发在宏观上是多任务同时运行,但是在任意时刻只有一个任务被处理。
实际场景中,可以通过多进程、多线程、协程等技术实现并发,通过向量化、GPU 计算等技术实现并行,从而充分利用 CPU 资源,减少空闲时间,提高程序性能。
指令级并行
CPU 通常具有多个执行单元 (如整数单元、浮点数单元),可以同时执行多个指令,这种技术称为指令并行 (Instruction-level parallelism, ILP)。以下是一些相关机制:
-
流水线 Pipeline:将 CPU 执行指令的过程划分为多个独立的阶段,通常包括取指令、译码、执行、访存、写回等,然后使用不同的硬件单元来并行执行不同阶段的指令。流水线可以提高 CPU 的效率,但如果遇到数据依赖或分支预测错误等问题,会导致流水线停顿。
-
乱序执行 Out-of-Order Execution (OOO):在 CPU 中使用重排序缓冲区来缓存乱序执行的指令结果,再将结果按照原有的顺序提交给 CPU。
-
预取 Prefetch:提前将下一条指令所需的数据从内存加载到 CPU 缓存中,避免因内存访问延迟而导致的指令停顿。
-
动态指令调度 Dynamic Instruction Scheduling:使用指令调度器动态地调整指令的执行顺序,优化指令的执行流程。动态指令调度通常在流水线中进行,通过分析先前已执行的指令,来决定下一个要执行的指令是哪一个,以避免潜在的数据冲突和分支预测错误。
-
分支预测 Branch Prediction:if-else 语句、for 循环等分支指令,在执行时会根据条件跳转到不同的代码块。由于其跳转目标不确定,CPU 可能会浪费很多时间在等待分支跳转的过程中。为了解决这个问题,CPU 使用分支预测机制,在执行分支指令之前预测下一个跳转的目标指令,并进行预取。如果预测错误,CPU 需要重新执行正确分支的所有指令。
局部性原理
CPU 访问内存的时间比执行指令要长得多。因此,CPU 内部通常拥有多级缓存,如 L1 缓存、L2 缓存、L3 缓存等。缓存越靠近 CPU,访问速度越快,但容量越小;相反,缓存的级别越高,容量越大,但速度越慢。
局部性原理指出,在计算机程序执行过程中,访问的数据和指令通常集中在空间上相邻的位置 (空间局部性),且会在一段时间内被反复使用 (时间局部性)。因此,CPU 可以通过预取等技术将需要访问的数据和指令提前载入到 CPU 高速缓存中,以降低访存延迟的影响。
当 CPU 访问内存时,它并不是仅仅把单个字节或单个字从内存中读取到缓存,而是以块为单位,一次性载入多个连续字节。这个单位称为缓存块 (Cache Line),其大小通常是 64 或 128 字节。如果 CPU 访问的数据和指令都集中在一个缓存块中,那么就可以一次性载入缓存,避免多次访问内存。
因此在编写代码时,应该尽可能地减少访问内存的次数,使用数组、结构体等数据结构,避免不规则的内存访问模式,充分利用缓存。
编译器优化
编译器会对源代码进行各种优化,以使生成的汇编代码更加高效。常见的优化手段有:
- 指令重排序:将程序中的语句按照一定的顺序进行排列,减少指令之间的相关性,提高指令并行度和 CPU 流水线效率。
- 常量折叠:在编译期间计算出常量表达式的结果,减少程序运行时的计算量。比如
i = 320*200*32会直接代替为2,048,000,而不是生成两个乘法指令。 - 常量传播:替换表达式中已知常量,这是一个持续传播的过程,会和常量折叠交错使用。
- 公共子表达式消除:识别重复的表达式,计算出结果并缓存,减少重复计算。
- 强制内联:将函数的代码直接嵌入调用者的代码中,减少函数调用的开销。
- 消除死代码:识别程序中不会执行的代码,并将其从程序中删除,减少程序的大小。
- 循环优化:对循环代码进行代码重排、循环展开、循环移位等操作,减少指令数量。
- 向量化:利用 CPU 的 SIMD 指令集,将程序中的标量计算转换为向量计算。
- 尾调用优化:当函数调用位于函数体尾部的位置时,这种函数调用称为尾调用。对于尾调用函数,CPU 可以不保留外层函数的调用记录,直接用内层函数取代。
在编写代码时,应注意代码的结构和风格,给予编译器相关提示,以方便编译器进行优化。
🔗 扩展阅读:编译优化 - OI Wiki、CSE 231 - LLVM Project、LLVM 循环优化器 Polly 架构
数据结构和算法
选择合适的数据结构和算法是提高程序性能的关键。
比如,C++ 提供了 unordered_set 和 set 来存储键值对。unordered_set 使用了哈希表实现,不保证元素的有序性,但是插入和查找的平均时间复杂度为 O(1)。set 使用红黑树实现,保证元素的有序性,但插入和查找的时间复杂度为 O(log n)。因此,如果需要有序地遍历元素,应该使用 set。如果需要高效地插入和查找元素,应该使用 unordered_set。
再比如,少量数据查询在不在,使用哈希表就可以实现。但海量数据查询在不在,位图或布隆过滤器可能是更合适的方式。
优化算法也可以降低程序的时间复杂度。比如使用快速排序代替冒泡排序,又或者在搜索过程中加入一些条件判断来剪枝、以及引入启发式搜索,提高搜索效率。
五、 代码层面的优化
💡 下文主要描述了 C++ 的优化方法。
使用静态分析工具
静态代码分析工具可以在不执行程序的情况下,发现潜在的代码问题,并给出优化建议。常见的 C++ 静态代码分析工具有 Clangd、Cppcheck、Coverity 等。我使用的是 Clangd,它提供了 VS Code 插件,能自动标识出不安全或低效率的代码,并给出 Quick fix 建议。
减少函数调用
函数调用会消耗时间和空间,可以使用宏定义和 inline 函数来内嵌代码。但如果代码过长,会降低编译期和运行期的性能。对于那些非常短小或者频繁调用的函数,可以用 inline 优化。
避免频繁创建和销毁对象
- 通过引用或指针传递参数,而不是通过值拷贝。
- for 循环里的
auto foo改成const auto& foo。 - 正确使用
std::move(),避免对象拷贝。
编写局部性原理友好的代码
- 使用连续的存储结构。比如使用数组代替链表,使用 vector 代替 set 等。
- 按照行优先遍历数组,而不是按照列优先。
使用高效的数据结构和算法
- string_view 和 span 是 C++ 的两个标准库,类比 string 和 vector。区别在于它们对外提供只读的数据,多个对象可以共享底层的内存,避免操作时的内存拷贝。
- 使用 flat_map、flat_set 等代替 map 和 set。前者使用了连续的内存空间存储键值对,相比于后者使用离散空间存储,遍历和随机访问的速度更快,但插入和删除操作变慢。
- 使用 f14 hash_table 代替 unordered_set。f14 在性能上有显著提升,尤其是在处理小数据集时的性能表现更佳。
- 使用 sonic-cpp 代替 rapidjson。sonic-cpp 利用向量化 (SIMD) 指令、优化内存布局和按需解析等关键技术,极大地提升了序列化、反序列化和增删改查的性能。
- 使用 PB 或 Thrift 等二进制数据格式,代替 JSON、XML 等文本格式。优点是序列化 / 反序列化效率更高,生成的数据更小。缺点是配置成本高,生成的数据人类不可读,
深入编译器优化
https://godbolt.org 是一个在线网页,可以实时将 C++ 代码编译成汇编指令,展示汇编指令和源码的对应关系,以及运行编译产物。支持 clangd、gcc 等多种编译器,支持自定义编译选项和添加外部依赖库。非常适合调试简单代码,或者深入分析编译过程。
- 打开 O2 或者 O3 等优化选项。O2 启用了许多常见的优化,如函数内联、循环展开和常量传播等。O3 在 O2 的基础上进一步优化代码,例如使用更高级的寄存器分配算法和更好的循环优化,但可能会导致编译时间变长。
- 使用
const、constexpr、consteval、constinit等关键字:constexpr:表达式、函数、变量可以在编译期计算得到结果consteval:函数必须在编译期计算得到结果constinit:变量必须在编译期完成初始化
- 为不会抛异常的函数添加
noexpect关键字。比如为移动构造函数加上此关键字,那么 vector 的push_back函数将调用移动构造函数,而不是默认的拷贝构造函数。 - 提高分支预测成功率:
- 使用
[[likely]]、[[unlikely]]修饰分支,提示编译器分支的进入概率。 - 使用
[[assume]]修饰表达式,提示编译器该表达式在运行时的结果必定为真。 - 将数据排序,保证按顺序遍历时,前 50% 数据进入 A 分支,后 50% 数据进入 B 分支 (Godbolt 示例)。
- 避免分支,将分支语句改为读取一个 bool 变量 (Godbolt 示例)。
- 使用
- 使用 SIMD 指令集,将程序中的标量计算转换为向量计算:
- 显式使用。例如使用第三方库,封装了多种使用 SIMD 指令集的函数。或者使用编译器提供的原生向量化指令。
- 隐式使用。编译器能够自动把某些循环代码优化为向量化指令,前提是我们要编写向量化友好的代码,比如不在循环里引入分支指令 (Godbolt 示例)。
使用 Auto FDO 优化技术
Auto FDO (自动反馈优化) 是一种编译器优化技术。它利用程序在运行时的性能数据,分析哪些代码路径被频繁执行,从而优化编译器生成的代码。本质上是利用真实的数据,反过来提高分支预测的成功率。实际场景中,程序的输入会经常变化,对应的代码路径分布也会变化。因此,即使是同一份代码,也需要定期重新运行 Auto FDO。
使用并发编程技术
如多进程、多线程、协程、异步 IO 等,提高 CPU 的利用率。
使用更高效的内存分配库
扩展阅读
- 《深入理解计算机系统 (CSAPP)》:这本书涵盖了汇编指令、处理器结构、程序优化、存储器结构等与上述性能优化手段密切相关的底层知识,配套有 CMU 的公开课 CS15-213 。强烈推荐学习。
- 《Effective C++》、《More Effective C++》、《Effective Modern C++》
- 《C++ 性能优化指南》
六、 系统架构层面的优化
优化硬件资源
如使用 SSD、扩大内存等,提升磁盘读写速度。或者增加集群机器数,但是要考虑成本。
利用缓存
缓存并不仅指 CPU 上的 L1 / L2 / L3 缓存。理论上总是可以用速度更快的存储作为慢速存储节点的缓存。比如在内存里维护一个本地文件的缓存,或者使用 redis 作为数据库的缓存等。使用缓存时,要注意为数据设置合理的过期时间,以及选择合适的淘汰算法。
数据库性能调优
数据库调优的目的是优化数据库访问和查询的耗时,常见的手段有加索引、分库分表等,这里不作展开。
容器化集群的优化手段
- 实现负载均衡,保证各个服务节点的资源利用率均匀。
- 开启自动弹性扩缩容策略。低流量时缩容,节约成本。高流量时扩容,降低负载。
- 潮汐集群。一般来说,在线业务在白天的流量很高,但晚上基本没有流量,冗余的机器资源正好可以给大数据、模型训练等离线任务使用。潮汐集群主要是为了节约成本,但通过资源共享,也变相地扩展了服务的计算资源。
限流和熔断
- 限流指控制服务以恒定的速率处理流量,多余的流量会被丢弃。这是为了在不确定和不稳定的流量环境中保证系统稳定运行。常见的限流算法有漏桶算法和令牌桶算法。
- 熔断指当下游服务因访问压力过大而响应变慢或失败时,上游可以暂时切断下游调用,以保护系统整体的可用性。
降级机制
- 降级指在服务出现故障或者超载等情况下,主动减少或者关闭一些服务,以保证核心服务正常运行。比如秒杀系统中,只更新缓存里的库存数,然后异步更新数据库。或者推荐系统中,使用高热内容代替个性化推荐内容。
- 对于核心服务,可以通过降低服务质量,来减轻系统压力。比如减少查询结果数量、降低返回的图片质量,减少精排服务的预估条数等。
- 服务降级应该是一种有计划、有条理和可控的行为,在出现故障之前就需要预先规划对应的降级预案。降级预案可以手动操作,也可以自动触发。
个性化的降级机制
- 引入流量价值预估机制,实现请求粒度的个性化降级。比如广告系统中,可以预估当前请求的价值,低于门槛的请求自动丢弃,不召回广告,节省算力。
- 引入剩余延时机制,根据请求在全链路的剩余延时,自动调节各个模块的降级参数。比如一个广告请求,如果前置链路耗时较短,那么可以给后续的精排模块传入更多的候选,以获得更好的点击效果。
- 引入算力分配机制。还是以广告系统为例,在系统层面,80% 的收入是由 20% 的广告贡献的,那么可以将这 20% 的广告和剩下的 80% 的广告拆分成两个数据库,分配不同的召回条数。在用户层面,可以结合流量价值预估,减少低价值请求的预估条数,将系统的算力更多地分配给高价值请求。
七、总结
性能优化是每个程序员的必修课。这既需要掌握相关基础知识,也需要有实际操作经验。
建议阅读《CSAPP》等经典书籍,并了解机器指令的原理,以更好地指导性能优化工作。线上服务在不断迭代,需要持续进行性能优化。每次性能优化后,必须通过基准测试和压力测试,验证性能优化的效果,让数据说话。
以上就是本文的全部内容,欢迎交流讨论。
参考文献
- 如何读懂火焰图 - 阮一峰
- Flame Graphs - Brendan Gregg
- Memory Leak (and Growth) Flame Graphs - Brendan Gregg
- Differential Flame Graphs - Brendan Gregg
- Perf Examples - Brendan Gregg
- 编译优化 - OI Wiki
- CSE 231 - LLVM Project
- LLVM 循环优化器 Polly 架构
- Open-sourcing F14 for faster, more memory-efficient hash tables
- 性能提升 2.5 倍!字节开源高性能 C++ JSON 库 sonic-cpp
- 浅析 C++ 性能优化方法和新特性 - Ads Infra Share
- 版权声明:本文采用知识共享 3.0 许可证 (保持署名-自由转载-非商用-非衍生)
- 发表于 2023-04-09,更新于 2023-04-09