📔【操作系统】详解阻塞、非阻塞、同步、异步
从进程调度谈起
现代操作系统(如 Windows、Linux 等)都是分时系统。分时系统允许同时允许多个任务,但实际上,由于一台计算机通常只有一个 CPU,所以不可能真正地同时运行多个任务。这些进程实际上是轮番运行,每个进程运行一个时间片。由于时间片通常很短,用户不会感觉到,所以这些进程看起来就像是同时运行。
每个进程的时间片由操作系统完成初始化,所有进程轮番地执行相应的时间。具体下一个时间片轮到哪个进程来执行,是由操作系统决定的,我们把操作系统选择下一个任务的过程称为“调度”。
当一个进程处于它的时间片时,正常情况下会独享 CPU,不断运行直到当前时间片被用完。但是让我们想象这样一个场景:当一个进程发起 open() 系统调用去读取某个文件的内容时,因为 CPU 的速度远远大于从硬件读取内容的速度,所以大部分时间 CPU 都在等待硬盘读取完成,这无疑造成了 CPU 浪费。
因此,当某个进程发起 open()、read() 等系统调用时,OS 会阻塞这个进程,让出 CPU 去执行别的任务。而读取任务实际上由 DMA 完成,当读取完毕后,DMA 会发出一个 I/O 中断通知 OS,OS 会从暂停位置继续这个进程。
有时候我们可能会看到这样的说法:“当某个进程发起阻塞调用时,它会被挂起”。阻塞是指进程在等待事件,暂时让出 CPU;挂起是指进程被换出到外存,等待激活。在讨论阻塞/非阻塞时,我们一般不区分“阻塞”和“挂起”,因为对进程而言,阻塞和挂起都是失去 CPU、无法运行的状态。当然,它们两个还是有一些细微的区别,可以查看[这篇文章]进一步了解。
阻塞、非阻塞
阻塞/非阻塞主要描述的是程序在等待调用结果返回时的状态:
- 阻塞调用:进程发起系统调用后,会被挂起,只有等系统调用返回后才能继续执行
- 非阻塞调用:进程发起系统调用后,系统调用会立即返回结果或者返回一个错误,不会阻塞当前进程。也就是说当前进程可以继续执行,不会让出 CPU
阻塞调用只能通过同步的方式获取返回结果。以 open() 系统调用为例,当进程调用 open() 时会被阻塞,等待调用返回。OS 转而调度其他进程,硬件同时开始准备。当硬件准备就绪后,会发出一个 I/O 中断通知 OS,OS 设置某些寄存器的值,以向进程传递参数,然后调起被阻塞的进程。进程此时获取到系统调用的返回值,将从暂停的位置继续执行。
非阻塞调用其实也是同步的方式。非阻塞调用需要调用方不停地轮询检查返回结果,直到返回成功,然后再开始处理。
同步、异步
这一小节让我们从程序员的视角,也即通用的编程模式的角度来讨论同步/异步的概念。这与操作系统无关,所以让我们暂时忘掉上一节的内容,重新开始吧。
简述
同步和异步的关注点在于消息通信机制:
- 同步调用的执行是一个有序的线性序列,当 A 调用 B 后,A 会主动等待 B 执行完成后再继续。比如 A 先后两次调用 B,记为 B(1),B(2),执行顺序一定是“A call B(1) -> B(1) run -> B(1) done, return A -> A call B(2) -> B(2) run -> B(2) done, return A -> A continue”。只有按照这种线性序列去执行程序,才能保证调用双方的状态同步。
- 异步调用是指当 A 调用 B 的时候,不等 B 执行结束,这个调用就会立即返回。当 B 执行完成后,B 会通过回调函数主动通知 A。异步调用并不是 FIFO 的,即 A 发起的多个调用并不是按照顺序收到通知的,有可能 A 后发出的调用却先收到了 B 的回应。
因此,同步和异步调用的关键区别就是被调用方(Callee)能否主动通知调用方(Caller)。如果 Callee 无法通知,那么 Caller 只能在每次调用时等待 Callee 执行结束,然后才能进行下一次调用,这就是同步的方式。而如果 Callee 能够主动通知,那么 Caller 在发起一次调用之后,可以直接执行其他的代码,也可以不等上次调用返回,立即发起下一次调用。Callee 会在执行结束时主动通知 Caller,Caller 会先跳转到回调函数那里处理这个事件,处理完成后再返回到原来的位置,继续往下执行。
异步调用的好处是将调用双方解耦,调用方在发起一个调用后,不需要关注被调用方的状态,而是被动地等待被调用方的通知。显然,同步调用是需要关注被调用方的状态的,只有等上次调用结束,才能发起下一次调用。
到这里,我们可以总结一下异步调用相比于同步调用的两个特点:
- 通知机制:被调用者可以在完成时主动通知调用者
- 非线性执行序列:① A 可以多次调用 B,不需要关注上次调用是否完成;② 多次调用的完成顺序并不是 FIFO 的,先调用的可能后完成
- 并行执行:如果串行执行的话那就和同步调用没什么分别了
这几个特点是异步调用的充分必要条件。当我们判断一个调用是同步还是异步的时候,只要判断它是否满足这几个条件即可。
实现方式
同步
同步的实现方式有等待和轮询。
在单线程的场景下,函数调用都是同步调用。如下所示,当 A 调用 B 后,无论 B() 会执行多长时间,A 都会等待,直到其返回执行结果。“等待”其实就是串行执行/顺序执行。
func B () {
// 做一些费时间的工作...
return result // 返回结果
}
func A () {
result := B() // A 调用 B
// 等 B 返回后,才能执行后续的任务
}
在多线程的场景下,可以使用轮询的方式实现同步:使用一个全局的标志位表示 B 的工作是否完成、再使用一个全局变量保存 B 的结果。A 可以不断轮询标志位直到其为 true,然后到全局变量中获取 B 的结果。如下所示:
var flag bool = false // B 是否完成,初始为未完成
var result Object =nil // 保存 B 的返回结果
func A () {
B() // A 先调用 B,这一行会立即返回
for flag != true {} // 不断轮询标志位,检查 B 是否完成工作
// 如果 B 的工作完成了,跳出循环,开始处理返回结果
process(result)
}
// 以下代码是用 golang 书写,你可以简单地把 go 关键字的作用理解为:创建一个新的线程
// 并在这个线程里执行其后面的函数。go 关键字不会阻塞原函数的执行,所以调用 B() 会立即返回
func B () {
go func() {
// 在一个新的线程里执行真正的工作
// 很多很多工作完成后...
flag = true // 设置标志位
result = someData // 设置结果
}
// 这里会立即返回,不会等待 go func... 执行完毕
}
即使 A、B 在两个线程里并行执行,A 也会一直在 for 循环那里空转,等待 B 执行结束。像这种情况还不如将 A 阻塞,让出 CPU。当然 A 也可以在轮询的过程中穿插一些自己的工作,充分利用多线程的优势,不要傻傻地等待:
for flag != true { // 不断轮询标志位,检查 B 是否完成工作
// 如果 B 的工作还没有完成,A 可以先做一点别的事
doSomeThing()
}
但这还是一种同步的方式。在这个示例里,A 依然需要不断地主动查询 B 是否执行结束,B 没有通知机制;A 对 B 的调用只能是线性的,即调用 B 后只能等其执行结束,才能继续下一次调用。
异步
异步的实现方式是回调函数或通知,这是一个概念。A 在调用 B 的时候,给 B 传一个回调函数作为参数,当 B 执行完成后,会调用这个回调函数,这相当于 B 通知了 A。
典型的异步模型是 Node.js,通过事件触发回调。这是一段基于回调的示例代码:
function A () {
// A 调用 B,并给 B 传递一个回调
B(func (result) {
process(result)
})
// 然后 A 就去做别的事了
doOtherThing()
}
/* ———————— 假设 A 和 B 并行执行 —————— */
function B (callback) {
// 很多很多工作完成后...
// 调用 callback,通知 A 工作完成了
callback(someData) // 可以通过参数给 A 传递一些数据
}
异步的应用场景
接下来让我们看看异步的应用场景。异步适合 CPU 不密集但是 I/O 密集的场景。
举个例子,假设有一个应用,负责从本地文件系统中读取文件并处理这些文件,假设读取文件需要 5 秒,处理它需要 2 秒。如果以同步的方式编写代码,那么只能按照 设备读取第一个文件 → CPU 处理第一个文件 → 设备读取第二个文件 → CPU 处理第二个文件 的线性序列来执行,但是在等待文件读取的过程中,CPU 其实是空闲的,这会造成极大的性能浪费。
相反,如果采用异步的方法,执行的顺序有可能是这样的:设备读取第一个文件 → CPU 处理第一个文件,同时设备读取第二个文件 → CPU 处理第二个文件,同时设备读取第三个文件。在这种情况下 CPU 处理和设备读取可以并行进行,提高了资源利用率。
再举一个例子,比如在编写一个爬虫程序的时候,需要访问 N 个 url 并且处理返回的网页内容。这个例子和上面“读取并处理多个文件的内容”非常相似,网络 I/O 和磁盘 I/O 都属于慢速场景,如果访问完一个 url 再访问下一个,CPU 大部分时间都在等待。这里可以采用异步的方式编写代码,使用多线程并行访问并处理每个 url。
程序层面的阻塞/非阻塞、同步/异步
- 阻塞/非阻塞关注的是单个进程的状态,区别在于进程是否被挂起
- 阻塞:某个调用会使得进程会被挂起,不占据 CPU,也无法执行;调用结束后恢复执行
- 非阻塞:某个调用会直接返回,进程不会被挂起,可以通过轮询的方式获取调用结果
- 同步/异步关注的是多次调用的执行顺序,区别在于是否必须线性执行以及是否可以回调通知
- 同步:依次执行,是一种线性序列;A 调用 B,B 执行完后才会返回,然后 A 继续执行
- 异步:并行执行,返回顺序不确定;A 调用 B 会立即返回,A 通过回调的方式获取调用结果
阻塞调用和非阻塞调用其实都是同步的。阻塞调用显而易见,一旦 A 发起一个阻塞调用,A 就会被挂起,等待调用返回时才能再继续执行。非阻塞调用在数据没有准备好时会返回一个错误,因此需要调用方轮询。等待和轮询都是同步的方式。
但是我们可以在高层封装这些同步调用,来支持异步的编程方式。
以 node.js 为例,node.js 提供的一系列接口比如发起网络请求、读取文件等都是异步的,需要传递一个回调函数来处理结果。比如读取文件的函数的签名为 fs.readFile(file[, options], callback),使用方法为:
fs.readFile("/etc/passwd", (err, data) => {
if (err) throw err;
console.log(data);
});
这里我们以异步的方式获取文件内容,但是在底层,node.js 使用的还是同步非阻塞的系统调用。之所以支持这种异步的写法,是因为 node.js 使用基于事件的方式而不是多线程的方式实现并发,它在一个进程里以单线程的方式运行一个事件循环,每次从事件队列中取出一个事件,然后运行该事件上的回调函数。
我们可以看到,程序框架能够通过高层的封装,在同步的接口上提供异步编程的能力。很多时候我们之所以容易将阻塞/非阻塞、同步/异步搞混,是因为我们总是在操作系统层面讨论前两个,却在程序框架层面讨论后两个。比如有人说:”非阻塞=异步,因为非阻塞和异步一样,都是调用后立刻返回,不需要等待这次调用完全结束“。这种说法之所以错误,是因为异步编程必须要一种通知的机制,如果被调用方无法通知,那只能靠调用方轮询,这就成了同步了。操作系统的非阻塞 I/O 并没有提供一种通知的机制,是我们使用的程序框架封装了这些系统接口,在更高层面上为我们提供了一种通知的机制(比如事件循环)。
内核层面的阻塞/非阻塞、同步/异步
接下来我们在内核层面讨论阻塞/非阻塞、同步/异步。
Unix 提供了 5 种 I/O 模型,除了上文讨论的阻塞 I/O、非阻塞 I/O,还有 I/O 复用(select/poll/epoll)、信号驱动和异步 I/O 模型(AIO)。只有异步 I/O 是符合异步 I/O 操作的含义的,其他四个都是同步 I/O。让我们来看看为什么。
一个 I/O 操作通常包括两个不同阶段:
- 发起 I/O 请求,等待数据准备好
- 实际的 I/O 操作:从内核向进程复制数据
第一个阶段区分的是阻塞 I/O 与非阻塞 I/O:如果发起 I/O 请求后会阻塞直到完成,那么就是阻塞 I/O,如果立即返回,那么就是非阻塞 I/O。
内核层面讨论同步/异步,主要关注的是第二个阶段。在执行实际的 I/O 操作时,如果进程会被阻塞,那就是同步 I/O,如果进程不会被阻塞,可以做别的事,那就是异步 I/O。
实际的 I/O 操作是指将数据由内核空间复制回进程缓冲区的操作。从实现层面来说,同步 I/O 需要进程来完成这个工作,所以在这个时间段它相当于在等待 I/O 完成;异步 I/O 由内核来完成 I/O 工作,完成后内核会通知进程,进程在等待 I/O 完成的这段时间可以做别的事。
下面这张图是《Unix 网络编程》中对 5 种 I/O 模型的总结:
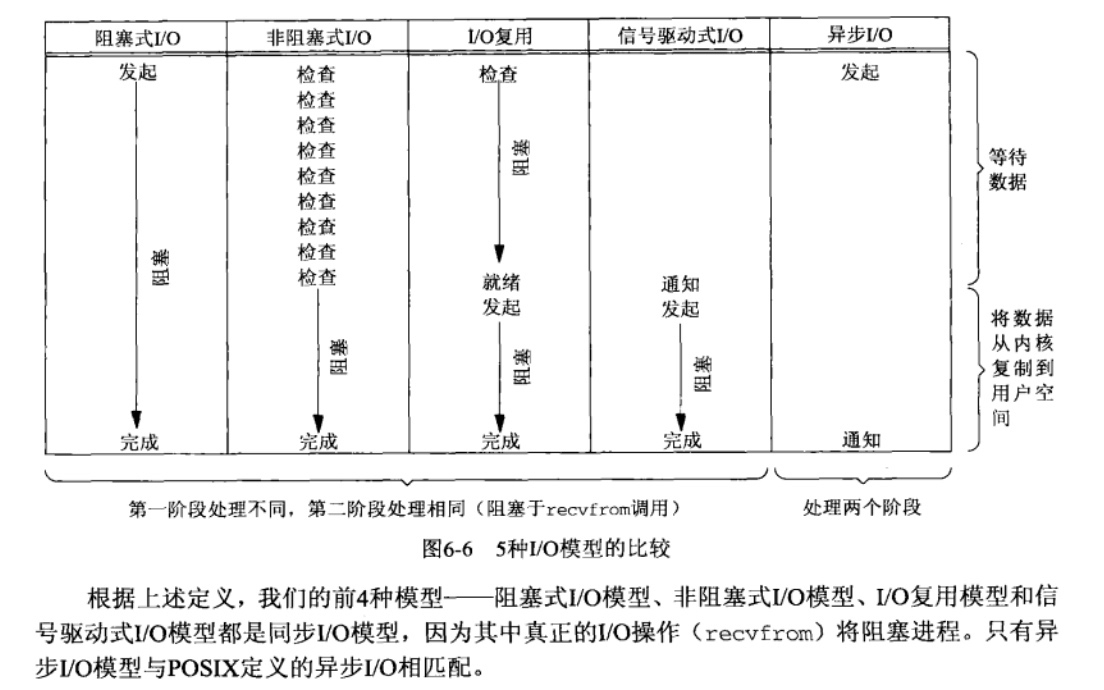
在内核层面,只有异步 I/O 模型是真正的异步。它实现了我们前面说的异步模式的三要素:
- 并行执行:确实,I/O 操作(复制数据的过程)和进程运行是同时进行的,I/O 不会阻塞进程的运行
- 通知机制:I/O 完成后由操作系统给进程发一个通知。这个通知可以用信号来实现:进程事先注册一个信号处理器 signal handler,当进程收到信号的时候会中断当前的操作,转去执行相应的 signal handler,结束后再返回中断的地方继续执行
- 非线性执行序列:肯定的,因为异步 I/O 在第一个阶段不会阻塞进程,所以进程可以多次发起异步 I/O 调用,不知道哪个先返回结果
所以确实只有 AIO 是符合异步定义的接口。
总结
异步同步的区别在于能否并行、被调用方能否主动通知、执行序列是否可以不是线性的。只有非线性执行的序列并且能并行运行,才是异步的,而这必须要一种通知机制来支持异步调用之间的消息通信。
阻塞 I/O 一定是同步的。非阻塞 I/O 需要轮询,也是同步的,因为其执行序列是线性的。
I/O 多路复用可以同时注册多个文件描述符,并且哪个文件描述符先就绪是不确定的,符合“非线性执行序列”,那它是不是异步的?不是,因为从程序的角度来看,I/O 多路复用不具有通知机制,进程需要主动调用 select 检查哪些描述符就绪。
I/O 多路复用的阻塞与非阻塞:通常我们称 I/O 多路复用是同步非阻塞的,这是因为它在第二个阶段(从内核向进程复制数据)采用的是非阻塞的 I/O 系统调用。但是进程在发起 select、epoll 等时还是会被阻塞。这相当于将阻塞点改变了位置,CPU 层面是非阻塞的,进程层面是阻塞的。
从流程上来看,使用 select 函数进行 I/O 请求和同步阻塞模型没有太大的区别。但是,使用 select 以后最大的优势是用户可以在一个线程内同时处理多个 socket 的 I/O 请求。用户可以注册多个 socket,然后不断地调用 select 读取被激活的 socket,即可达到在同一个线程内同时处理多个 I/O 请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
所以 I/O 多路复用是:多路、同步、阻塞的模型(CPU 层面非阻塞,进程层面阻塞)。相对的,阻塞 I/O 是:单路、同步、阻塞的模型。
参考资料:
- 推荐阅读:【再议 I/O】阻塞、非阻塞、同步、异步:这篇文章详细分析了 UNIX 的五种 I/O 模型的异同,在不同层次讨论了阻塞、非阻塞、同步、异步,讨论了广义的异步和侠义的异步。
- 怎样理解阻塞非阻塞与同步异步的区别? - 大姚的回答 - 知乎
- 怎样理解阻塞非阻塞与同步异步的区别? - 银月游侠的回答 - 知乎
- 版权声明:本文采用知识共享 3.0 许可证 (保持署名-自由转载-非商用-非衍生)
- 发表于 2019-11-15